What Topic Modeling?
For any human reading and understanding huge amount of text is not possible, in order to that we need a machine that can do these tasks effortlessly and accurately. These tasks is called Natural Language Understanding (NLU) task. NLU task is to extract meaning from documents to paragraphs to sentences to words.
At the document level, the most useful ways to understand text by its topics. The statistical process of learning and extracting these topics from huge amount of documents is called topic modeling.
Topic modeling is a soft/fuzzy clustering technique where each instance belongs to each cluster to a certain degree (percentage/probability).
- Group similar words together
- Group similar document/comments together
Topic Modeling in Machine Learning spectrum:
Let’s see where topic modeling fit in machine learning spectrum.

Unsupervised learning: where data is not structured and don’t have labels.
Also Read:
Topic Modeling Application:
- The New York Times move their recommendation engine to collaborative topic modeling from collaborative filtering to recommend articles to people.
- ‘Historying’ a large set of texts (See ‘Martha’s Ballard‘ from Stanford’s Cameron Blevins.)
Topic Modeling Techniques:
There are so many techniques to do topic modeling. Among them 4 most popular techniques are:
1. LSA (Latent Semantic Analysis)
2. pLSA (Probabilistic Latent Semantic Analysis)
3. LDA (Latent Dirichlet Allocation)
4. Deep Learning based lda2vec
In this post I will concentrate on only Latent Dirichlet Allocation (LDA)
How to Build LDA Model:

As other models LDA need same steps to provide output.

Graphical representation of LDA:

K: Number of topics
N: Number of words in the document
M: Number of documents to analyze
α : Per-document topic distribution
High α means every document is likely to contain a mixture of most of the topics and not just any single topic specifically.
Low α means A document is more likely to be represented by just few of the topic.
β : Per topic word distribution
High β means each topic is likely to contain a mixture of most of the words not just any word specifically.
Low β means topic may contain a mixture of just a few of words.
φ(k): Word distribution for topic k (Topic probability per word)
ϴ(i): Topic distribution for for document I (Topic probability per document)
Z(i,j): Topic assignment for w(i,j)
w(i,j): j-th word in i-th document
Explanation of Graphical representation of LDA:
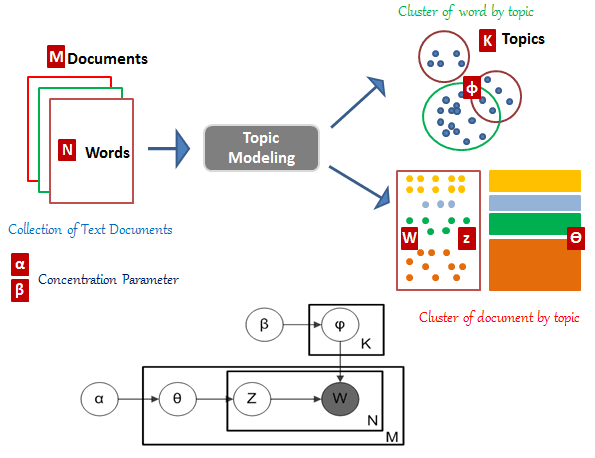
W: Word
Z: Topic
LDA Input:
1. M no. of documents
2. Each of these documents have N no. of words
3. Which needs to pass through LDA


LDA Output:
- K no. of topics (cluster of words)
- Φ distribution (document to topic distribution)
How to Train LDA Model:

LDA is an iterative algorithm which follows below steps to train and tune model. Those are:
1. Initiate parameters(α, β)
1. Initiate parameters(α, β)
2. Initialize topic assignments randomly
3. Iterate: For each word in each document re-sample topic for each word.
4. Produce result after all iteration is completed.
5. Evaluate final model.
How many topics/Dimension:

So we know how to do topic modeling and analyze topic modeling. Now one thing I missed that to train LDA you should define number of topics at the very beginning like K-Means.
So how many topics we should go for?
It depends on application domain.
Here the goal is not to label or classify documents but to be able to compare them focusing on their latent similarities and do this in such a way that it would make sense for a human reader.
Though by coherence score you can have an idea about number of topics but it is not the rule of thumb technique. You need to experiment with various values, starting with 2 to infinite.
Conclusion:
In this topic I have discussed about:
- What is Topic Modeling
- Topic modeling in Machine Learning Spectrum
- Different types of topic modeling
- How to build LDA
- Graphical representation of LDA
- Explanation of LDA Graphical Representation
- How to train LDA model
- How many topics should be.
If you have any question or suggestion regarding this topic, feel free to type in comment section below. I will try my best to answer those.
It is incredibly, very user-friendly and user friendly. Great job for the fabulous site.
Thanks
This is some good quality material. It took me a while to find this blog but it was worth the time. I noticed this page was buried in bing and not the first spot. This webpage has a lot of fine stuff and it does not deserve to be burried in the search engines like that. By the way Im going to save this blog to my favorites.
Ive been meaning to read this and just never acquired a chance. Its an issue that Im very interested in, I just started reading and Im glad I did. Youre a terrific blogger, one of the finest that Ive seen. This weblog definitely has some data on topic that I just wasnt aware of. Thanks for bringing this stuff to light.
Thanks pertaining to spreading this particular good content material on your web site. I came across it on the internet. I will check to come back once you publish much more aricles.
Very good post for Latent Dirichlet allocation for brginners.
to design an interactive LDA model for related legal judgments ?