Doc2vec is based on word2vec. If you do not familiar with word2vec (i.e. skip-gram and CBOW), you may check out my previous post. Doc2vec also uses unsupervised learning approach to learn the document representation like word2vec.
The main motivation of doc2vec is to represent document into numeric value. There are so many ways to do it like:
- Doc2vec
- Weighted sum of word vectors
- Skip thought vectors
- Bag-of-words
- TF-IDF
- FastSent
- …etc
In this post I will explain what is doc2vec, how it’s built, how it’s related to word2vec and what can you do with it.
Now somewhere you may heard terms like sentence2vec (sentence vector) or paragraph2vec (paragraph vector). All are same thing. Note: Mikolov and Le used term Paragraph vector in their paper and gensim implemented this in package called doc2vec.
Must Read:
- Complete Guide for Natural Language Processing
- Continuous Bag of Words (CBOW) – Single Word Model – How It Works
- Continuous Bag of Words (CBOW) – Multi Word Model – How It Works
- Skip-Gram model – How it works
Doc2vec Architecture
As you know doc2vec is based on word2vec and the main motivation of doc2vec is to create numeric representation of documents.
Now words maintain logical (grammatical) structure but documents don’t have any logical structures. To solve this problem another vector (Paragraph ID) needs to add with word2vec model. This is the only difference between word2vec and doc2vec.
Note: Paragraph ID is unique document ID.
Now like word2vec there are two flavor of doc2vec are available:
- Distributed Memory Model of Paragraph Vectors (PV-DM)
- Distributed Bag of Words version of Paragraph Vector (PV-DBOW)
Distributed Memory model:
Distributed Memory (DM) model is similar to Continuous-Bag-of-Words (CBOW) model in word2vec which attempts to guess the output (target word) from its neighboring words (context words) with the addition of a paragraph ID.
Let’s say we have one document:
I like natural language processing
And we will be predicting next word for a given word.
So model will look like below:

Distributed Bag of Words:
Distributed Bag-Of-Words (DBOW) Model similar to skip-gram model of word2vec, which guesses the context words from a target word.
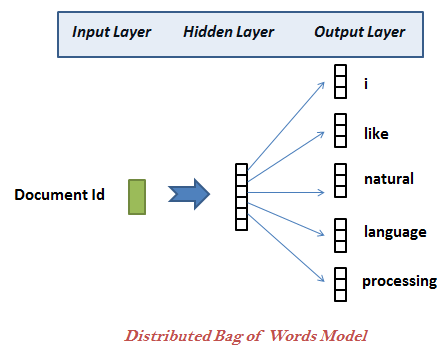
There is only one difference between skip-gram and distributed bag of words (DBOW) is instead of using the target word as the input, Distributed Bag of Words (DBOW) takes the document ID (Paragraph ID) as the input and tries to predict randomly sampled words from the document.
Must Read:
Conclusion:
Now a question should appear in your mind that PV-DM or PV-DOBOW which is better.
Well this is depend on your project requirement. If you are using short sentences then PV-DBOW may works well and train faster than PV-DM.
But in general as per my observation PV-DM performs better than PV-DBOW but takes longer time to train.
If you have any question or suggestion regarding this topic please let me know in comment section, will try my best to answer.