Word2Vec is one of the biggest and most recent breakthroughs in Natural Language Processing (NLP). The concept is easy to understand. Now let’s understand word2vec first to proceed further.
What is Word2vec?
The main objective of Word2Vec is to generate vector representations of words that carry semantic meanings for further NLP tasks. Each word vector can have several hundred dimensions and each unique word in the corpus is assigned a vector in the space. For example, the word “man” can be represented as a vector of 4 dimensions [-1, 0.01, 0.03, 0.09] and “woman” can have a vector of [1, 0.02, 0.02, 0.01].
Is it unsupervised learning?
It depends on your views. If you keep data pre-processing separate then it is supervised learning but if you consider whole process starting from data pre-processing to output, then it is unsupervised learning.
To implement Word2Vec, there are two flavors which are — Continuous Bag-Of-Words (CBOW) and continuous Skip-gram (SG). In this article I will discuss about skipgram model only, I have separate article for CBOW model. I will recommend you to have a look at single word CBOW model first to proceed this article.
Now let’s understand what is continuous Skip-gram (SG) or Skip gram model is?
Must Read:
- Continuous Bag of Words (CBOW) – Single Word Model – How It Works
- Continuous Bag of Words (CBOW) – Multi Word Model – How It Works
Continuous Skip-gram (SG):
It guesses the context words from a target word. This is completely opposite task than CBOW. Where you have to guess which set of words can be nearby of a given word with a fixed window size. For below example skip gram model predicts word surrounding word with window size 4 for given word “jump”

The Skip-gram model is basically the inverse of the CBOW model. The input is a centre word and the model predicts the context words.
In this section we will be implementing the Skipgram for multi-word architecture of Word2Vec. Like single word CBOW and multi word CBOW the content is broken down into the following steps:
1. Data Preparation: Defining corpus by tokenizing text.
2. Generate Training Data: Build vocabulary of words, one-hot encoding for words, word index.
3. Train Model: Pass one hot encoded words through forward pass, calculate error rate by computing loss, and adjust weights using back propagation.
Output: By using trained model calculate word vector and find similar words.
I will explain CBOW steps without code but if you want full working code of Skip-Gram with numpy from scratch, I have separate post for that, you can always jump into that.
1. Data Preparation for Skip-gram model:
Let’s say we have a text like below:
“i like natural language processing”
To make it simple I have chosen a sentence without capitalization and punctuation. Also I will not remove any stop words (“and”, “the” etc.) but for real world implementation you should do lots of cleaning task like stop word removal, replacing digits, remove punctuation etc.
After pre-processing we will convert the text to list of tokenized word.
Output:
[“i”, “like”, “natural”, “language”, “processing”]
2. Generate training data for Skip-gram model:
Unique vocabulary: Find unique vocabulary list. Here we don’t have any duplicate word in our example text, so unique vocabulary will be:
[“i”, “like”, “natural”, “language”, “processing”]
Now to prepare training data for multi word Skipgram model, we define “context word” as the word which follows a given word in the text (which will be our “target word”). That means we will be predicting surrounding word for a given word.
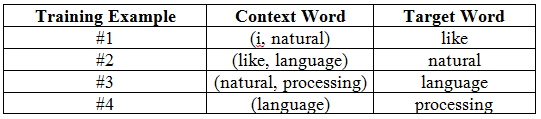
Now let’s construct our training examples, scanning through the text with a window will prepare a context word and a target word, like so:

For example, for context word “i” and “natural” the target word will be “like”. For our example text full training data will looks like:
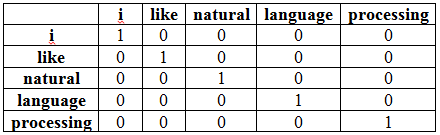
One-hot encoding: We need to convert text into one-hot encoding as algorithm can only understand numeric values.
For example encoded value of the word “i”, which appears first in the vocabulary, will be as the vector [1, 0, 0, 0, 0]. The word “like”, which appears second in the vocabulary, will be encoded as the vector [0, 1, 0, 0, 0]
So let’s see overall set of context-target words in one hot encoded form:
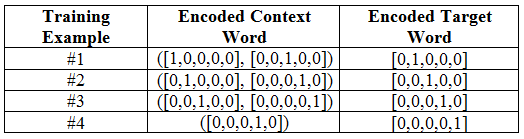
So as you can see above table is our final training data, where encoded context word is Y variablefor our model and encoded target word is X variable for our model as skipgram predicts surrounding word of a given word.
Now we will move on to train our model as we are done with our final training data.
3. Training Skip-gram Model:

Multi-Word skip-gram Model with window-size = 1
Model Architecture of Skip-gram:
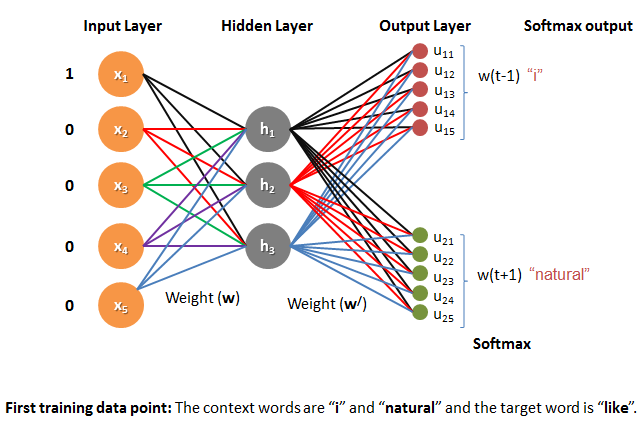
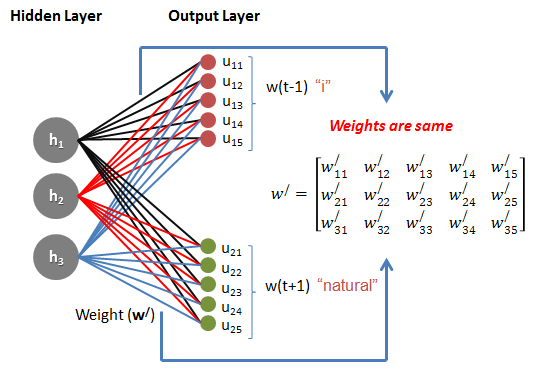
Now here we are trying to predict two surrounding words that is why number of nodes in output layer is two. It can be any number depending on how many surrounding word you are trying to predict. In above picture 1st output node represents previous word (t-1) and 2nd output node represents after word (t+1) of given input word.
The number of nodes in each output layer (u11 to u15and u21 to u25) are same as the number of nodes in the input layer (count of unique vocabulary in our case is 5). This is because we are dealing with each word in the vocabulary for each context.
The whole process of training for skip-gram is exactly same as single word CBOW (Continuous bag of word) except two things. I will explain only those two points here.
Must Read:
- Continuous Bag of Words (CBOW) – Single Word Model – How It Works
- Continuous Bag of Words (CBOW) – Multi Word Model – How It Works
i). Weight Calculation of Skip-gram model:
Weight matrix for input to hidden layer (w):
We can define our weight matrices in the similar manner like single word CBOW model.

And weight matrix for hidden to output layer (w/).

Only one important note: Weight for each hidden layer to output layer is same.
ii). Error Calculation of Skip-gram:
In single word CBOW model we were predicting single word so error calculation was simple there. But in skip-gram model we are predicting multiple words so we need to do some trick here. The trick is simple we will just take summation of all errors. It is clear that for skipgram model number of errors are same as number of context window (in our case 2).
So, if we consider “C” as the total number of context window then error:

Rest training and updating weights process will be same as single-word CBOW model, where we only need to replace ‘e’ with ‘summation of e’
For single word CBOW model loss function was:

So generalized loss function of skipgram should look like:

One difference apart from error you can clearly observe that,

that is because for CBOW output was single but for Skipgram the number of output is same as number of context window.
Keeping total “C” context window and total unique vocabulary size as “V”.
“j” is position of a word. For example “j” for word “i” in our example is 1 and for word “natural” is 3.
[“i”, “like”, “natural”, “language”, “processing”]
And j* is the actual output word in every context window.
Now let’s conclude with listing all generalized equations.
Forward Propagation for Skip-Gram model:

Back Propagation for Skip-gram model:
Update second weight (w/):
General Vector Notation:

Note:Symbol ⊗ denotes the outer product. In Python this can be obtained using the numpy.outer method
Update second weight (w):
General Vector Notation:

Note:Symbol ⊗ denotes the outer product. In Python this can be obtained using the numpy.outer method
If you have any question or suggestion regarding this topic see you in comment section. I will try my best to answer.
I found some useful information in your blog, it was awesome to read, thanks for sharing this great content to my vision, keep sharing.
Very useful